
Régi sztori már, hónapokkal ezelőtt meg akartam írni, csak mindig volt valami, ami épp előrébb volt a teendőlistámon, de most már csak sikerült. Elsőre talán meglepő a párosítás, hiszen a KFC étlapja szerint algoritmussal nem kérhetjük a menünket, de mégis van valami kapocs közöttük. Hosszabb írás erről a bizonyos kapocsról azoknak, akik szívesen tanulnának ma valami újat.
Kezdjük a legelején, és haladjunk időrendben! Március elején került ki a SiHuHu-ra Hunor cikke arról, hogy milyen káros a mekis kaja. Nem sokkal ezután kaptunk egy emailt a SiHuHu szerkesztőségétől (micsoda kulisszatitok!), amiben témaötletek voltak, amikről lehetne cikkeket írni. Ebben szerepelt ez is:
„A mekis cikkre »rácáfolva« szeretnénk egy cikksorozatot indítani a különbőző gyorsétterem- és áruházláncokról: KFC? Starbucks, Burger, Subway, IKEA, Tiger, Lush stb. A kedvencedet bemutathatod röviden.”
De mit adott nekünk a Meki?
Nekünk, a XII.-ben például csoportkeretet idénre (Tizenkettő. Te teszed azzá, ami.) De ezen kívül is van egy említésre méltó érdekesség. A közgazdaságtanban mindenféle ijesztő kifejezések (pl. vásárlóerő-paritás, még leírni is nehéz) és mérőszámok vannak arra, hogy egy ország gazdaságát, jólétét jellemezzék. Az egyik ilyen pedig a Big Mac-index, ami az alapján rangsorolja az országokat, hogy mennyibe kerül ott helyi áron (dollárra átszámolva) egy Big Mac átlagban a Mekikben. Menő dolgok ezek, ha érdekel titeket a téma, ebben a 2015-ös cikkben olvashattok még róla.
Természetesen tisztában vagyok vele, hogy a cikk igaz, a mekis kaja valóban egészségtelen, meg minden; így nem is cáfolatként, sokkal inkább játékos visszavágásként terveztem írni egy cikket sokunk kedvenc gyorsétterme, a KFC védelmében. Leírtam volna, hogy milyen ütős a fűszerkeverék a panírban, mennyi találgatás van a pontos összetételről, hogy a nem ledarált hús csak nem lehet olyan egészségtelen, hogy milyen jó baráti beszélgetések/bármilyen ifi megbeszélések alakulhatnak ki egy soha ki nem ürülő újratölthető Pepsi mellett, meg ilyenek.
Ezt a hirtelen felindulásomat, hogy erről én majd cikket írok, pedig gondoltam meg is osztom Zsuzsival, akivel – talán nem túlzás a kifejezés – van némi gyorskaja fétisünk, ami leginkább főnixmadárként újra és újra feltámadó „nem eszem gyorskaját”-hónapokban (hetekben/napokban/órákban), illetve Sajtburger menüről szóló belsős poénokban nyilvánul meg.
Így történt, hogy felütésként elküldtem neki Messengeren a fent már idézett felhívást:
„A mekis cikkre »rácáfolva« szeretnénk egy cikksorozatot indítani a különbőző gyorsétterem- és áruházláncokról: KFC? Starbucks, Burger, Subway, IKEA, Tiger, Lush stb. A kedvencedet bemutathatod röviden.”
És túlzás nélkül mondom, hogy egy percen belül (16:51-kor küldtem az üzenetet, és 16:51-kor készült a screenshot is) már egy Subway hirdetés mosolygott vissza rám a Messengerben (amibe egyébként azt hiszem valahogy akkortájt kerültek reklámok.)
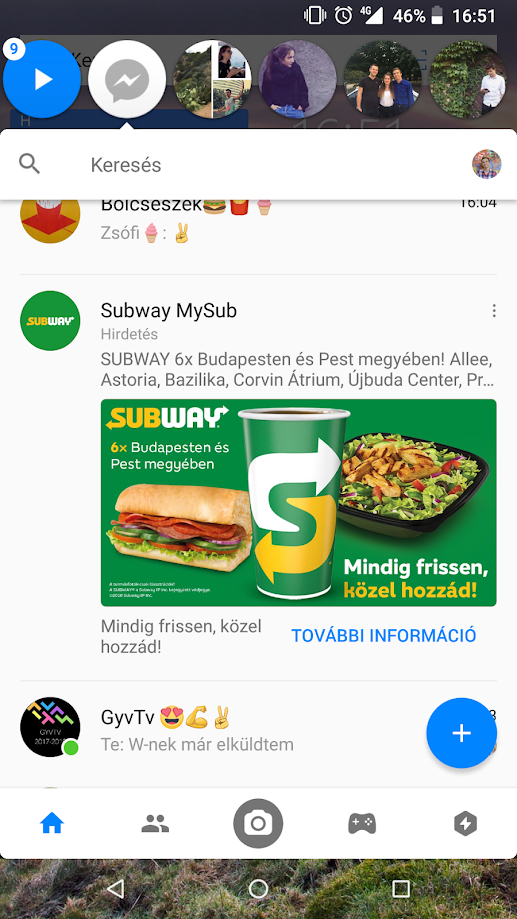
Oké, de mi ebben a nagy dolog? Ez is egy nagyon jó példa arra, hogy hogyan működnek az ingyenes online szolgáltatások, mint pl. a Facebook és a Messenger is. A böngészőben és az appokban megjelenő hirdetési felületek ugyanis sokkal értékesebbek, mint pl. az utcán egy óriásplakáthely. Emiatt tudnak „ingyenesek” lenni ezek a szolgáltatások, mert ezeket a hirdetési felületeket célzottan tudják értékesíteni.
Leegyszerűsítve: ha az utcán kitesznek egy óriásplakátot, akkor minden ember ugyanazt a terméket fogja látni rajta, így azok is, akik szinte biztosan nem fognak belőle vásárolni. Az interneten viszont nagyon sok „nyomot” hagyunk magunk után, amik alapján egészen jól „ki tudják találni”, hogy nekünk mit érdemes hirdetni. Ez történt valószínűleg ebben a konkrét esetben is: mivel leírtam egy üzenetben a Subway szót, az algoritmus azt gondolta, érdemes nekem Subway hirdetést feldobni.
Ez azt jelenti, hogy ugyanaz az oldal mindenkinek más és más?
A hirdetések szempontjából biztosan, de valójában ennél is többről van szó. A Facebook hírfolyamunk összeállításától elkezdve megannyi példát találunk arra, amit angolul filter bubble jelenségnek hívnak. Ennek a lényege nagy vonalakban az, hogy inkább olyan dolgokkal találkozunk az interneten, amikről az oldal azt hiszi, hogy szeretjük azt/egyetértünk vele. Jó példa erre az, hogy ha a Google-ben rákeresünk ugyanarra a dologra más helyről/időben/böngészőből/fiókból/stb., merőben más keresési eredményt kaphatunk (pl. egy Egyiptomra irányuló keresés valakinek politikai viszályokról szóló cikkeket, másnak nyaralási ajánlatokat jelenít meg elsőként.) Pár év múlva érdemes lehet megnézned ezt a videót a témáról.
Ezek a „nyomok”, amiket hagyunk az interneten, nagyon sokfélék lehetnek: Google-keresések, Instagram-szívecskék, YouTube videómegtekintések, Facebook-oldalak kedvelései, vagy egyszerűen csak az, hogy hány órakor használjuk a gépünket. Ezek mind-mind olyan adatok, amikből ha nagyon sok áll egy cég rendelkezésére (egy Google vagy Facebook méretű cégnél pl. ez adott, hiszen rengeteg a felhasználójuk), akkor már nagyon sok nagyon is hasznos információt tud belőlük kinyerni.
Az pedig, hogy ezekből az adatokból hogyan lesz információ, már egy külön tudomány, pontosabban több tudomány vegyítése (matematika, informatika, szociológia, pszichológia, meg ilyenek.)
Big Data, a jelen egyik legmenőbb kifejezése
Ha érdekel ez a téma (ami egyébként TÉNYLEG nagyon érdekes), itt van ez a TED videó, amiben ugyan angolul, de magyar felirattal magyarázzák el negyed órában, kb. miről is van szó, és miért lesz ez a következő évtizedekben slágertéma. Ha most nem is szánod még rá magad, pár év múlva mindenképp érdemes lesz megnézned, hidd el!
Zárszóul csak annyit, hogy ezt a jelenséget nagyon sok helyen fel lehet ismerni, és ha tudjuk, hogy így működnek a dolgok, az talán hozzásegít minket ahhoz, hogy legalább egy kicsit tudatosabbak legyünk.




Hozzászólás